AIは「考える機械」じゃない
AIのアウトプットはどのようにすれば変わるのか。今回はプロンプトを与えた時、LLMとどのようなやりとりがされているのかを簡潔に示すこととした。
LLM(大規模言語モデル)は「思考する人間」ではなく、「次に来るトークン(単語の断片)を確率で予測するエンジン」である。
この仕組みを理解すると、「なぜ指示を具体的に書くと回答が改善するのか」が自然に腑に落ちる。
LLMが文章を生成する4つのステップ
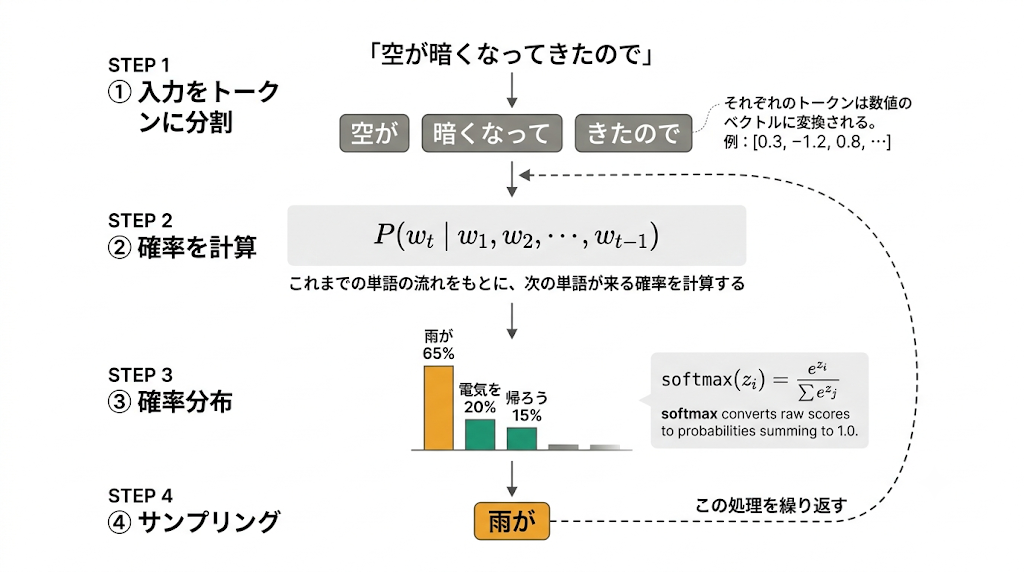
上の図を見てほしい。LLMが「空が暗くなってきたので」という入力から次の言葉を出すまでに、内部では次の処理が走っている。
① 入力をトークンに分割する
入力されたテキストはまず「トークン」という単位に細かく切り分けられ、それぞれが数値のベクトル([0.3, −1.2, 0.8, …] のような数字の配列)に変換される。LLMが扱うのは言葉ではなく、あくまでこの数値の配列だ。
② 次のトークンの確率を計算する
ここが核心だ。LLMは以下の計算をしている。
「これまでに並んだすべての単語 w₁, w₂, …, w_{t-1} を前提として、次の単語 w_t が来る確率はどれくらいか」
P( w_t | w_1, w_2, …, w_{t-1} )
「意味を理解して答えを考えている」のではなく、「文字列の流れから統計的に続きやすい言葉を計算している」というのが実態だ。
③ 全語彙に確率分布が割り当てられる
計算の結果、語彙全体に対して確率が割り振られる。「雨が 65%」「電気を 20%」「帰ろう 15%」といった具合だ。この変換にはsoftmax関数(softmax(z_i) = e^z_i / Σe^z_j)が使われ、すべての確率の合計がちょうど1.0になるよう調整される。
④ 最も確率の高いトークンを選択し、また②に戻る
確率分布の中から1つのトークンが選ばれ(サンプリング)、それが出力される。そのトークンは次のステップでは「これまでの入力」の一部として追加され、また②から同じ計算が繰り返される。この繰り返しで、1文字ずつ文章が積み上がっていく。
「役割を与える」と何が変わるのか
「役割を与える」と何が変わるのか
プロンプトに「あなたは高校の理科の先生です」と書くだけで、回答の質がガラッと変わることがある。なぜそんなことが起きるのか。
答えは②の確率計算にある。
LLMが次のトークンを選ぶ計算式 P( w_t | w_1, w_2, …, w_{t-1} ) の「条件」部分——w_1, w_2, …, w_{t-1}——には、プロンプトに書いたすべての文字列が含まれる。つまり「あなたは理科の先生です」という一文も、確率計算の前提条件として丸ごと組み込まれる。
その結果が下の図だ。
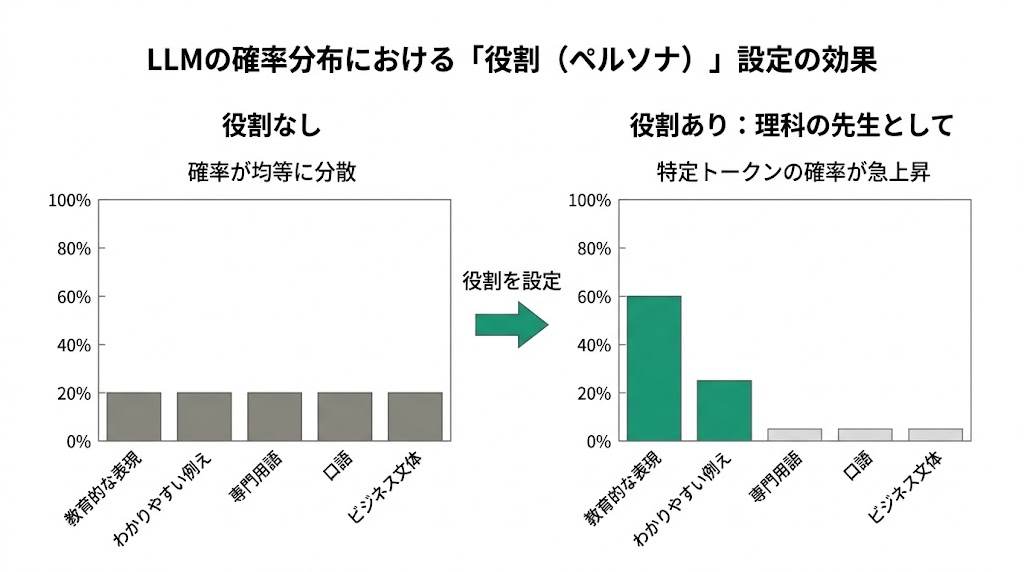
役割なしのとき、「教育的な表現」「わかりやすい例え」「専門用語」「口語」「ビジネス文体」といった語彙はどれも似たような確率で並んでいる。AIはどのトーンで答えればいいかわからないまま計算を走らせるので、結果として全方向に無難な、平均的な出力になる。
「理科の先生として」と設定したとたん、「教育的な表現」と「わかりやすい例え」の確率が急上昇し、それ以外は相対的に下がる。AIが選ぶトークンの候補が自然に絞られるため、専門的かつ読みやすい回答が出やすくなる。
ただしここに落とし穴がある。役割設定は確率分布を「偏らせる」操作なので、強くかけすぎると偏りすぎる。「第一線の研究者として」のような高度な専門家ロールを設定すると、今度は専門用語の確率が跳ね上がりすぎて、かえって読みにくい出力になることがある。
役割と対象読者をセットで書くのが効果的なのはこのためだ。
- 役割だけ:「あなたは理科の先生です」→ 専門性は上がるが読者層が定まらない
- 役割+対象読者:「あなたは理科の先生です。高校1年生に向けて説明してください」→ 「教育的」かつ「平易」な語彙に確率が集中する
役割は「どの分野の語彙を使うか」を決め、対象読者は「どの難易度の語彙を使うか」を決める。この2つが揃って初めて、確率分布が狙い通りの場所に絞り込まれる。
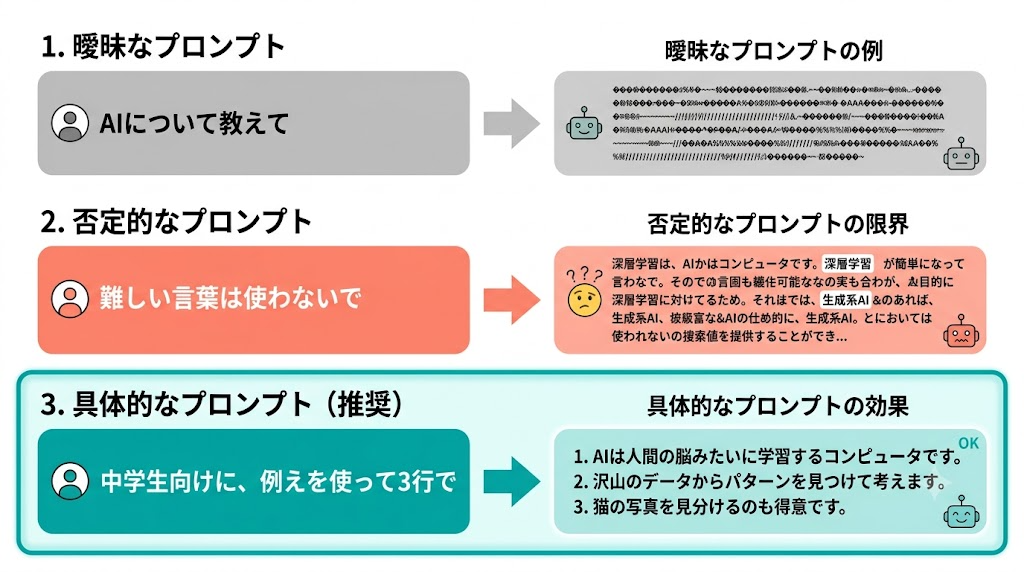
「具体的な指示」でAIの迷いをゼロにする
②の計算で確率が広く分散しているとき——つまり「どのトークンも似たような確率」の状態——AIは結果として平均的で凡庸な出力を返す。
具体的な制約を与えることは、この確率の分散を強制的に潰す操作だ。「3行で」「箇条書きで」「中学生にわかるように」といった指示を加えると、それ以外のトークンが選ばれる確率が大きく下がり、AIが迷う余地がなくなる。余計な選択肢が消えるので、内容の精度も上がるし、事実と違うことをでっち上げる(ハルシネーション)も起きにくくなる。
また、否定的な指示(「難しい言葉は使わないで」)は逆効果になりやすい。②の条件に「難しい言葉」というトークンが入ることで、かえってそこに計算の注目が向いてしまうからだ。禁止するより「中学生でもわかる言葉で」と言い換えるほうがずっと効果的だ。
実際に試せるテクニック
| やりたいこと | プロンプトの書き方の例 |
|---|---|
| 専門的な内容をわかりやすく | 「高校1年生向けに、身近な例えを使って3行で説明して」 |
| 特定のトーンで書いてほしい | 「フレンドリーな先生として、会話口調で答えて」 |
| 構造的に整理したい | 「まず要点を3つ箇条書きにして、その後に詳しく説明して」 |
| より良い回答のために質問してほしい | 「回答の前に、必要な情報をAI側から3つ聞いて」 |
| 段階的に考えてほしい | 「まず構成案を作り、それを確認してから本文を書いて」 |
まとめ:AIに「お願い」するのではなく「設計する」感覚で
LLMは指示を「解釈」しているのではなく、与えられた文字列を前提に②の確率計算を回しているだけだ。
だからプロンプトを丁寧に書くことは「AIへのお願い」じゃなく、「次のトークンが選ばれる確率分布を設計する作業」だと考えると腑に落ちる。役割・対象読者・形式・長さをちゃんと伝えれば、AIが①〜④のループで選ぶべきトークンは自然に絞られる。逆に、指示が雑なときは確率が広く分散したまま計算が走り、平均的な出力しか返ってこない。AIのアウトプットの質は、半分以上が指示の設計で決まる。

